
- Видео 698
- Просмотров 4 024 240
Spark Summit
Добавлен 25 авг 2013
Videos related to Spark Summit data science and data engineering conference.
Bay Area Apache Spark Meetup @ Intel
Intel: Tech -Talk-1: Distributed Deep Learning At Scale on Apache Spark with BigDL
Databricks: Tech-Talk-2: Easy, Scalable, Fault-tolerant stream processing with Structured Streaming in Apache Spark
Databricks: Tech-Talk-2: Easy, Scalable, Fault-tolerant stream processing with Structured Streaming in Apache Spark
Просмотров: 10 544
Видео


Women in Big Data Lunch at Spark Summit East
Просмотров 2 тыс.7 лет назад
Panel Discussion with Ziya Ma, Nick Dimtchev, Julie Greenway and Gunjan Sharma moderated by Donna Fernandez
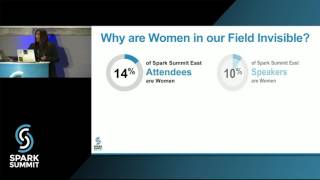
The Leaky Pipeline Problem: Making your Mark as a Woman in Big Data:by Kavitha Mariappan
Просмотров 2,7 тыс.7 лет назад
Women in Big Data Keynote at Spark Summit East

Apache Spark Meet Up at Spark Summit East 2017
Просмотров 4,5 тыс.7 лет назад
Apache Spark Meet Up at Spark Summit East 2017

Using Spark and Riak for IoT Apps-Patterns and Anti Patterns: Spark Summit East talk by Pavel Hardak
Просмотров 2,3 тыс.7 лет назад
Everybody agrees that IoT is changing the world… and creates new challenges for software developers, architects and DevOps. How can we build efficient and highly scalable distributed applications using open-source technologies? What are characteristics of data generated by IoT devices and how it differs from traditional enterprise or Big Data problems? Which architectural patterns are beneficia...
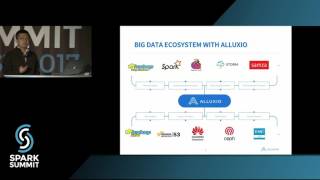
Effective Spark with Alluxio: Spark Summit East talk by Gene Pang and Haoyuan Li
Просмотров 3,3 тыс.7 лет назад
Alluxio, formerly Tachyon, is a memory speed virtual distributed storage system and leverages memory for storing data and accelerating access to data in different storage systems.. Alluxio has a quickly growing open source community of developers and users and is deployed at such organizations as Alibaba, Baidu, Barclays, Intel, Huawei, and Qunar. Many of these deployments use Alluxio with Spar...

Utilizing Spark as the Analytical Core to an Open Source HTAP Relational Database: John Leach
Просмотров 1,6 тыс.7 лет назад
Utilizing Spark as the Analytical Core to an Open Source HTAP Relational Database on HBase Splice Machine utilizes Spark on Yarn as the analytical execution architecture for our open source HTAP relational database. This talk will walk through how a dual engine architecture can exist where Spark supports analytical queries and large database maintenance operations (HBase Compactions, Index Main...

Building Real Time BI Systems with Kafka, Spark & Kudu: Spark Summit East talk by Ruhollah Farchtchi
Просмотров 14 тыс.7 лет назад
One of the key challenges in working with real-time and streaming data is that the data format for capturing data is not necessarily the optimal format for ad hoc analytic queries. For example, Avro is a convenient and popular serialization service that is great for initially bringing data into HDFS. Avro has native integration with Flume and other tools that make it a good choice for landing d...

The Fast Path to Building Operational Applications with Spark: talk by Nikita Shamgunov
Просмотров 2 тыс.7 лет назад
The Fast Path to Building Operational Applications with Spark: talk by Nikita Shamgunov
Kerberizing Spark: Spark Summit East talk by Abel Rincon and Jorge Lopez-Malla
Просмотров 1,2 тыс.7 лет назад
Spark had been elected, deservedly, as the main massive parallel processing framework, and HDFS is the one of the most popular Big Data storage technologies. Therefore its combination is one of the most usual Big Data’s use cases. But, what happens with the security? Can these two technologies coexist in a secure environment? Furthermore, with the proliferation of BI technologies adapted to Big...
Optimizing Spark Deployments for Containers: Isolation, Safety & Performance by William Benton
Просмотров 3,8 тыс.7 лет назад
Developers love Linux containers, which neatly package up an application and its dependencies and are easy to create and share. However, this unbeatable developer experience hides some deployment challenges for real applications: how do you wire together pieces of a multi-container application? Where do you store your persistent data if your containers are ephemeral? Do containers really contai...
Auto Scaling Systems With Elastic Spark Streaming: Spark Summit East talk by PhuDuc Nguyen
Просмотров 2,6 тыс.7 лет назад
Come explore a feature we’ve created that is not supported out-of-the-box: the ability to add or remove nodes to always-on real time Spark Streaming jobs. Elastic Spark Streaming jobs can automatically adjust to the demands of traffic or volume. Using a set of configurable utility classes, these jobs scale down when lulls are detected and scale up when load is too high. We process multiple TB’s...
Secured Kerberos based Spark Notebook for Data Science: Spark Summit East talk by Joy Chakraborty
Просмотров 3,7 тыс.7 лет назад
This presentation will provide technical design and development insights in order to set up a Kerberosied (secured) JupyterHub notebook using Spark. Joy will show how Bloomberg set up the Kerberos-based Spark-notebook-integrating JupyterHub, Sparkmagic, and Levy. Sparkmagic provides the Spark kernel for Scala and Python. Livy is one of the most promising open source software to allow to submit ...
Apache Toree: A Jupyter Kernel for Spark: Spark Summit East talk by Marius van Niekerk
Просмотров 4,9 тыс.7 лет назад
Apache Toree: A Jupyter Kernel for Spark: Spark Summit East talk by Marius van Niekerk
Teaching Apache Spark Clusters to Manage Their Workers Elastically: Erik Erlandson and Trevor Mckay
Просмотров 1,2 тыс.7 лет назад
Devops engineers have applied a great deal of creativity and energy to invent tools that automate infrastructure management, in the service of deploying capable and functional applications. For data-driven applications running on Apache Spark, the details of instantiating and managing the backing Spark cluster can be a distraction from focusing on the application logic. In the spirit of devops,...
Building a Dataset Search Engine with Spark & Elasticsearch: talk by Oscar Castañeda-Villagrán
Просмотров 12 тыс.7 лет назад
Building a Dataset Search Engine with Spark & Elasticsearch: talk by Oscar Castañeda-Villagrán
Building Realtime Data Pipelines with Kafka Connect & Spark Streaming by Ewen Cheslack-Postava
Просмотров 13 тыс.7 лет назад
Building Realtime Data Pipelines with Kafka Connect & Spark Streaming by Ewen Cheslack-Postava
Apache Carbondata: An Indexed Columnar File Format for Interactive Query by Jacky Li/Jihong Ma
Просмотров 4 тыс.7 лет назад
Apache Carbondata: An Indexed Columnar File Format for Interactive Query by Jacky Li/Jihong Ma
Lessons Learned from Dockerizing Spark Workloads: Spark Summit East talk by Tom Phelan
Просмотров 4 тыс.7 лет назад
Lessons Learned from Dockerizing Spark Workloads: Spark Summit East talk by Tom Phelan
Time Series Analytics with Spark: Spark Summit East talk by Simon Ouellette
Просмотров 6 тыс.7 лет назад
Time Series Analytics with Spark: Spark Summit East talk by Simon Ouellette
New Directions in pySpark for Time Series Analysis: Spark Summit East talk by David Palaitis
Просмотров 6 тыс.7 лет назад
New Directions in pySpark for Time Series Analysis: Spark Summit East talk by David Palaitis
Keeping Spark on Track: Productionizing Spark for ETL: talk by Kyle Pistor and Miklos Christine
Просмотров 9 тыс.7 лет назад
Keeping Spark on Track: Productionizing Spark for ETL: talk by Kyle Pistor and Miklos Christine
Spark: Data Science as a Service: Spark Summit East talk by Shekhar Agrawal and Sridhar Alla
Просмотров 2,1 тыс.7 лет назад
Spark: Data Science as a Service: Spark Summit East talk by Shekhar Agrawal and Sridhar Alla
Accelerating Spark Genome Sequencing in Cloud-A Data Driven Approach by Eric Kaczmarek and Lucy Lu
Просмотров 4597 лет назад
Accelerating Spark Genome Sequencing in Cloud-A Data Driven Approach by Eric Kaczmarek and Lucy Lu
Spark Autotuning: Spark Summit East talk by: Lawrence Spracklen
Просмотров 2,9 тыс.7 лет назад
Spark Autotuning: Spark Summit East talk by: Lawrence Spracklen
Fault Tolerance in Spark: Lessons Learned from Production: Spark Summit East talk by Jose Soltren
Просмотров 4,6 тыс.7 лет назад
Fault Tolerance in Spark: Lessons Learned from Production: Spark Summit East talk by Jose Soltren
Lambda Processing for Near Real Time Search Indexing at WalmartLabs: talk by Snehal Nagmote
Просмотров 4,1 тыс.7 лет назад
Lambda Processing for Near Real Time Search Indexing at WalmartLabs: talk by Snehal Nagmote
Sparking Up Data Engineering: Spark Summit East talk by Rohan Sharma
Просмотров 1,6 тыс.7 лет назад
Sparking Up Data Engineering: Spark Summit East talk by Rohan Sharma
Spark Streaming as a Service with Kafka and YARN: Spark Summit East talk by Jim Dowling
Просмотров 2,6 тыс.7 лет назад
Spark Streaming as a Service with Kafka and YARN: Spark Summit East talk by Jim Dowling
Learnings Using Spark Streaming and DataFrames for Walmart Search: by Nirmal Sharma and Yan Zheng
Просмотров 2,5 тыс.7 лет назад
Learnings Using Spark Streaming and DataFrames for Walmart Search: by Nirmal Sharma and Yan Zheng
Watching in 2024
I'm invading Shanghai 🎉
discontinued :(
Excelent
NJ😮
Thank you for this video what about spacy instead of stanford? did you try it?
the answers to almost all my questions on the topic are given in 26 min video. Awesome!
Great work Sameer, the depth and clarity which you explain is just outstanding. Could you please help me with the PPTs url, i am not able to find it in link attached in description.
Can I get to know the design of your reward function? And when bidding for 24 hours, how do you make sure that which actions are best to take and how did you model the problem?
A good analysis.
She says it, folks. Whatever handful of women stay in “tech” pursue “feminine” positions. The speaker is in Marketing, Sharon heads the Customer Success department, Maddy takes over Product Management and Val leads the Design team. Just because the company is tech doesn’t mean it’s stem. The speaker explains nothing really of the reasons why 1) many women leave STEM fields and 2) the women who stay choose “feminine” positions
Me encanta su estilo ella es hermosa.
Good
Hi, by any chance has anyone made notes for this lecture?
This is pathetic!
Great talk and explanation of the Tdigest algorithm as well as Erik's excellent implementation of the same. ASCII plots were unexpected and impressive :D
_
Excellent. Best wishes.
and now we have chatGPT
really wonderful talk!
damn 5 years ago...i absolutely loved the presentation engaging is a difficult job..u did great also is it me or anyone else..these 2 faces looks too familiar by the time video ends
good
excellent. it would definitely gonna help. it would great if you could share sqlVis_ggplot_raster wrappers
my head = 1min.:D
this still a relevant video? thanks
it's. All the features he mentioned (and many more that came after related to this) were rolled-out to productive Spark.
Still waiting for streaming Random Forest (
Great session, well presented. In QA session the query on groupByKey, is a valid one. For immutable types like string using groupByKey over reduceByKey is preferred.
Hii.. this is one of the best presentation about spark. One question is, Spark evolved a lot from here. Are these concepts still relevant till today? Any changes or obsolete content of this video? Can any one tell me pls.
Thanks! I'm surprised to see that this video is still being watched since it's 8 years old 😳 I would say that like 75% of it is still accurate. Even if it's not accurate, watch it for the fancy graphics and jokes man.
Thank you this is very helpful!
This is one of the best free videos ever available on the youtube community.
Well, it can't compete with 3 blue 1 brown's educational videos. Those are on another level.
Just want to share. I came across this video back in 2016 when spark was a buzz word mostly. Did not understand most of it back then and did not watch it. Now again watching it in 2022. It's true gem.
is this video still relevent? I am new to spark and came across this video should I watch it?
Definitely. It will help you understand the core fundamentals of spark and many other things. Though some of the points might be irrelevant now, but that is not deal breaker.
Aww, my goal with it was to on-board completely new folk to Spark. Sorry if it was confusing first time you watched it.
Kandungan video sangat baik, tahniah
Great presentation , the croud is like shit no support nothing
Thanks for superbly breaking down the mistakes and their solutions. Thanks for the excellent presentation.
LESGOOOOO KENT!
min 9 it starts talking about best practices
kķcjòkyfhfhgup
I say Ban "Megzie Ssyk"!
that was an amazing explanation!
Nice video
Where can I get these slides?? Thanks in advance
You must travel back to 2015 for the slides.
This presentation is not about fraud prevention. As an audience member said, the title is a fraud. 👎
audio level is very low
good explanations , this would be great if some git code they can mention
debugged a problem by following steps as you explained. Thank you very much. (2022 april)
this is wonderful, enjoyed start to end :)
Great talk sir, you have cleared topics
One of the best videos to learn about Spark Structured Streaming. Watched this once, back in the end of 2020...still relevant.
Could you please demonstrate how to retain decimal value when we write the data frame in json format. Eg : one of my column in df has a value of 12.00 when I write this df into a json file df.write.json(“user/my path/“) . The json file written in this path will have “column”:12.0 instead of 12.00.
Is there a code available for this ??